Scaling the Future: How DeepSeek LLM is Redefining Open-Source Language Models
From Data Alchemy to Hyperparameter Wizardry — A Deep Dive into the Evolution of LLMs

The Evolution of LLMs: From Chatbots to AGI Aspirants.
The evolution of language models has been nothing short of revolutionary. From humble beginnings as simple pattern-matching systems to today’s complex AI assistants, each leap forward has redefined the boundaries of what machines can understand, generate, and reason. But as models scale from millions to billions of parameters, a crucial challenge emerges: How do we make them bigger, smarter, and more efficient without running into diminishing returns?
This is where DeepSeek LLM shines. More than just another large model, it’s a blueprint for the next generation of AI — one that carefully balances compute, data quality, and architectural efficiency.
Imagine language models as cities. Early models like GPT-2 were small villages — functional but limited. GPT-3 expanded into a bustling town, and today’s LLMs like LLaMA-2 and DeepSeek are metropolises, teeming with “inhabitants” (parameters) and intricate infrastructure. But building these cities isn’t just about adding more buildings; it’s about optimizing roads (data), zoning laws (hyperparameters), and utilities (compute).
The DeepSeek LLM paper is a masterclass in urban planning for AI. It tackles a critical question: How do we scale models efficiently while balancing compute, data, and architecture? Let’s break down their blueprint.
Pre-Training: The Art of Data Alchemy
A great language model isn’t just about size — it’s about data quality. Training an LLM is like preparing a Michelin-star dish: no matter how advanced the kitchen (compute) or how skilled the chef (model), the final outcome depends on ingredient quality (data).
DeepSeek’s 2-trillion-token multilingual dataset (Chinese/English) isn’t just a massive dump of internet text. It undergoes a three-stage purification process to extract the highest-quality linguistic patterns:
1. Deduplication: Removing the Noise
- Web scrapes like Common Crawl are filled with redundancy — identical or near-duplicate text.
- DeepSeek processed 91 dumps, eliminating 89.8% redundant content to prevent the model from memorizing repeated phrases instead of learning true patterns.
- Impact: Improves model generalization and reduces overfitting.
2. Filtering: Separating Gold from Gravel
- Not all text is useful — low-quality, irrelevant, or synthetic content can degrade training.
- DeepSeek applies linguistic and semantic filtering to retain high-quality human-written text.
- Impact: Ensures that the model learns from rich, structured knowledge rather than low-grade internet noise.
3. Remixing: Balancing the Knowledge Spectrum
- Data imbalance is also another common pitfall. Most web corpora are dominated by casual conversations, news, and general text, while technical fields like code and math are underrepresented.
- DeepSeek strategically adjusts token distributions to ensure strong performance in coding, mathematics, and multilingual reasoning.
- Impact: Enhances the model’s ability to reason logically, understand code, and generate structured outputs.
Lastly, Think of this three phrases as refining crude oil. Deduplication removes impurities, filtering isolates premium fractions, and remixing blends them for optimal performance.
Architecture: Building Skyscrapers, Not Sprawl.
While some models grow wide (adding more parameters indiscriminately), DeepSeek focused on depth and efficiency — like a city building skyscrapers instead of sprawling suburbs.
1. Model Scale: Going Deep, Not Just Wide
- 67B parameters distributed across 95 layers, prioritizing depth over width.
- Why it matters: Deeper models could capture hierarchical patterns in language better than shallow models with the same parameter count.
2. Grouped-Query Attention (GQA): Faster Inference, Lower Latency
- Traditional attention mechanisms slow down with large models.
- DeepSeek adopts Grouped-Query Attention (GQA), where multiple queries share the same key-value representations.
- Result: 30% speedup in inference while maintaining performance.
3. Tokenizer Innovations: Breaking Down Numbers for Better Math
- DeepSeek uses a 100K vocabulary (compared to LLaMA-2’s 32K).
- Key improvement: Splits numbers into digits (e.g.,
"12345"→["1", "2", "3", "4", "5"]). - Why? LLMs struggle with long numbers because traditional tokenizers treat them as single unknown tokens. Breaking them into digits improves numerical reasoning.
# Tokenizer handling numbers
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("deepseek-ai/deepseek-llm-67b")
print(tokenizer.tokenize("The value is 12345"))
# Output: ['The', ' value', ' is', '1', '2', '3', '4', '5']Hyperparameters: The Symphony Conductor
Training a large language model requires careful orchestration of hyperparameters, much like a symphony conductor guiding an orchestra. A poorly tuned learning schedule can lead to overfitting if too aggressive or underfitting if too cautious. To optimize performance, DeepSeek employs a multi-step learning rate schedule rather than the traditional cosine decay approach. The training begins with a 2,000-step warmup phase, where the learning rate (LR) gradually increases to its peak value. Then, as training progresses, the LR undergoes two major drops: at 80% of total tokens, it decreases to 31.6% of the peak value, and at 90% of tokens, it further declines to 10%.
This structured decay approach helps maintain training stability over long runs. Unlike cosine decay, which can reduce the learning rate too aggressively and limit late-stage improvements, multi-step decay paces the training process strategically. It’s similar to training an Olympic marathon runner — starting with a gradual build-up, maintaining steady endurance, and reserving energy for final refinements. If the learning rate remains high throughout, the model can overfit quickly; if it drops too soon, it may never reach its full potential. By gradually adjusting the LR at critical points, DeepSeek ensures that the model refines its learning efficiently without burning out early.
Beyond learning rate scheduling, DeepSeek also optimizes batch size and gradient accumulation steps, ensuring that even with a 2-trillion-token dataset, training remains stable. This fine-tuning prevents gradient explosions in deep architectures and allows for more efficient compute utilization across large-scale GPU/TPU clusters.
Scaling Laws: Cracking the Code of Growth
For years, AI researchers have debated the optimal balance between model size and training data. Earlier work by Kaplan et al. (2020) suggested that increasing model parameters was the key to better performance, while Hoffmann et al. (2022) (Chinchilla scaling laws) found that focusing on more data and smaller models led to greater efficiency. DeepSeek refines these theories by introducing a crucial insight: data quality dictates the optimal scaling strategy.
Scaling a model isn’t just about adding more tokens or increasing parameter count; it’s about ensuring that each training token is high-quality and informative. If a student studies from poorly written textbooks, they will struggle to learn, no matter how much they read. Conversely, if they have access to expertly crafted materials, they can grasp concepts more efficiently, reducing the need for endless repetition. Similarly, DeepSeek prioritizes data curation before model scaling, allowing it to train larger models using fewer but higher-quality tokens — a significant refinement of Hoffmann’s scaling laws.
To fine-tune model growth, DeepSeek follows precise power-law relationships to determine optimal batch size and learning rate based on the compute budget C.
To illustrate, consider a scenario where a 1e20 FLOP compute budget is available. Using DeepSeek’s scaling laws, the optimal learning rate and batch size can be calculated as follows:
C = 1e20
eta_opt = 0.3118 * (C ** -0.125)
batch_opt = 0.292 * (C ** 0.327)
print(f"Optimal LR: {eta_opt:.2e}, Batch Size: {int(batch_opt)}")
# Output: Optimal LR: 3.16e-5, Batch Size: 512DeepSeek also makes a crucial distinction in model-data scaling trade-offs. When training on high-quality datasets, the optimal strategy is to allocate more compute to model expansion — increasing depth and parameter count. However, when dealing with noisier datasets, the model should prioritize processing more tokens to compensate for the lower signal-to-noise ratio. This adaptive scaling approach allows DeepSeek to maximize learning efficiency based on the dataset’s characteristics, rather than following a one-size-fits-all scaling law.
The Model-Data Tango: Finding the Perfect Balance
Scaling large language models is a delicate dance between model size and data volume. DeepSeek refines traditional scaling laws by shifting the focus from parameter count (NNN) to a more meaningful metric: non-embedding FLOPs per token (MMM). This approach captures actual computational effort rather than just raw parameter growth.
DeepSeek’s findings reveal a dynamic relationship between compute, model scale, and data quality:
- When data quality is high, it’s more efficient to scale up the model’s capacity rather than increasing token count. This follows the relation model FLOPs should grow faster than compute in high-quality data environments.
- When data quality is lower, allocating more compute to processing additional tokens is preferable. This follows a narrative where data token count increases almost as fast as compute to compensate for noisier inputs.
This insight fine-tunes the Chinchilla scaling laws by emphasizing data quality as the key determinant. Instead of blindly increasing either model parameters or training tokens, DeepSeek adjusts the balance dynamically based on dataset reliability. In effect, the model isn’t just scaling — it’s scaling smartly.
Alignment: From Base Model to Conversationalist
Pre-training gives an LLM raw knowledge, but alignment transforms it into a useful, safe, and human-friendly AI. DeepSeek refines this process through Supervised Fine-Tuning (SFT) and Direct Preference Optimization (DPO) — two techniques that fine-tune the model for better instruction following and safer outputs.
Supervised Fine-Tuning (SFT): The Apprenticeship Phase
SFT is like guiding an apprentice — a direct training phase where the model learns to follow human instructions from carefully curated examples. DeepSeek’s SFT dataset includes 1.5 million multilingual instructions, enabling it to develop strong reasoning, coding, and problem-solving abilities.
Evaluation: Benchmarks and Beyond
In the competitive landscape of language models, performance benchmarks are the ultimate proving ground. DeepSeek 67B doesn’t just hold its own — it excels, often outshining larger models like LLaMA-2 70B across various domains. Take a look:
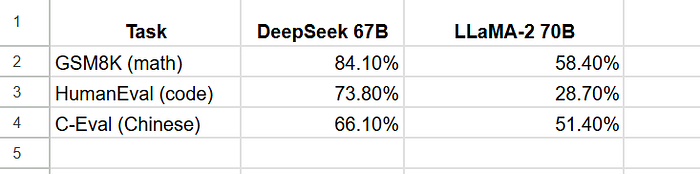
DeepSeek’s impressive lead in math (GSM8K) and code (HumanEval) demonstrates its robust ability to understand complex patterns and generate precise solutions — critical skills for both technical and everyday applications. Its performance in Chinese (C-Eval) also highlights its strength in multilingual comprehension, though this leads us into areas for further growth.
Beyond traditional benchmarks, real-world challenges reveal even more about a model’s capabilities. For instance, in LeetCode Contests, DeepSeek managed to solve 17.5% of the problems — commendable, but still lagging behind GPT-4’s 48.4%, showing room for growth in problem-solving and real-time reasoning. In the Hungarian Math Exam, DeepSeek scored 58 out of 100, nearing the average human performance — a remarkable feat for an AI but also a reminder of the gap between artificial and human cognition in nuanced reasoning.
The Road Ahead: Challenges & Ambitions
Despite its accomplishments, DeepSeek isn’t without limitations. A key challenge is its knowledge cut-off, having been trained on data up to May 2023. This restricts its understanding of recent events, developments, and emerging trends — something future iterations will need to address, perhaps through continuous training pipelines or dynamic updating mechanisms.
Another hurdle lies in its multilingual capabilities. While it excels in Chinese and English, DeepSeek struggles with less-represented languages. This limitation points to an inherent imbalance in its training data and an opportunity for future improvements. Expanding language diversity in datasets and employing techniques like cross-lingual transfer learning could pave the way for more comprehensive language support.
Conclusion: The Long Game of LLMs
DeepSeek isn’t just another large language model — it’s a blueprint for the future of AI scaling. By combining rigorous scaling laws, high-quality data curation, and architectural innovations, it redefines what open-source models can achieve. Rather than blindly increasing parameters or data volume, DeepSeek prioritizes efficiency, adaptability, and long-term sustainability, setting a new benchmark for the field.
Yet, as the authors themselves acknowledge, today’s models are only the beginning — “mere initial steps toward AGI.” The true challenge lies not just in making models larger but in making them more intelligent, generalizable, and aligned with human needs. With frameworks like DeepSeek leading the charge, the roadmap to next-generation AI is becoming increasingly clear.
In the race to build smarter, more capable AI, victory doesn’t belong to the fastest sprinter — it belongs to the most enduring marathoner. DeepSeek is lacing up its shoes, and the real journey is just beginning. 🚀
References
- DeepSeek LLM Paper (https://arxiv.org)
- GitHub Repository (https://github.com/deepseek-ai/deepseek-LLM)
Enjoyed this breakdown? Clap, share, and follow for more deep dives into AI research! 🚀